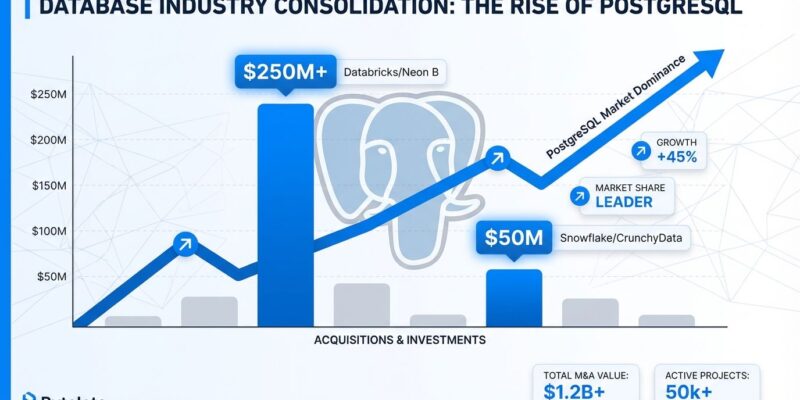
2025 was the year PostgreSQL became inevitable. Over $1.25 billion flowed into PostgreSQL companies alone—Databricks paid $1 billion for Neon in May, Snowflake grabbed CrunchyData for $250 million in June—while every major database vendor rushed to ship Model Context Protocol servers for AI agent access. This wasn’t hype; it was validation of a fundamental market shift.
Based on Carnegie Mellon Professor Andy Pavlo’s comprehensive database retrospective, 2025 marks the end of the specialized database era. PostgreSQL consolidation, mandatory AI integration, and legal threats to open-source compatibility layers are rewriting the rules for engineering leaders making database choices in 2026.
PostgreSQL Wins: $1.25B Validates the Shift
Databricks dropped $1 billion on Neon, a serverless PostgreSQL provider, in May 2025. The kicker? Over 80% of Neon’s databases are now provisioned by AI agents, not humans clicking buttons in admin panels. Databases have become infrastructure that code deploys, not something developers manually configure.
Snowflake followed with a $250 million acquisition of CrunchyData in June, bringing enterprise-grade PostgreSQL support generating over $30 million in annual recurring revenue into its platform. Both acquisitions sent the same message: specialized databases are losing to PostgreSQL plus extensions.
PostgreSQL replaced MySQL as the #1 database in Stack Overflow’s 2023 developer survey, and three competing distributed PostgreSQL projects emerged this year—Multigres, Neki, and PgDog—racing to solve horizontal scaling, the last major technical gap. “PostgreSQL’s flexibility and maturity now outweigh the appeal of specialized systems,” Pavlo notes. “This concentration of capital around a single open-source system reflects a fundamental shift in how enterprises view database strategy.”
Moreover, the “right tool for the job” orthodoxy is crumbling. PostgreSQL with pgvector for embeddings, TimescaleDB for time-series, and PostGIS for geospatial data covers what used to require MongoDB, InfluxDB, and specialized spatial databases. Default to PostgreSQL unless you have an exceptional reason not to.
MCP Servers: AI Integration Becomes Table-Stakes
Every major database vendor released Model Context Protocol servers in 2025, making AI integration mandatory rather than optional. Roughly 700 MCP servers now exist for tools like Google Drive, Slack, GitHub, Postgres, and Puppeteer. OpenAI adopted MCP across ChatGPT products in March, and Anthropic donated the protocol to the Linux Foundation’s Agentic AI Foundation in December.
However, security remains broken. Knostic’s July 2025 scan found nearly 2,000 MCP servers exposed to the internet with zero authentication. Unrestricted LLM agent access to production databases creates massive data exposure risks that most implementations ignore. Consequently, the June 2025 MCP specification update adds OAuth Resource Server classification, but adoption lags.
Databases without MCP support will be excluded from AI agent workflows. But the rush to ship features has outpaced security hardening. Engineering teams need MCP integration with proper authentication, access controls, and audit logging—not just exposed database connections.
Consolidation and Failures: Market Maturity Signals
IBM alone spent $14 billion acquiring database and data infrastructure companies in 2025: $3 billion for DataStax (NoSQL and vector databases) in May and $11 billion for Confluent (real-time data streaming) in December. Furthermore, Fivetran and dbt Labs merged to create a comprehensive ETL platform. Private equity firms acquired plateau-stage database companies like Couchbase, SingleStore, and MariaDB.
Meanwhile, five database startups failed. Fauna shut down in May with a blunt admission: “Driving broad-based adoption of a new operational database globally is very capital intensive,” and their board determined they couldn’t raise sufficient capital. Voltron Data, PostgresML, Hydra, and MyScaleDB also shut down operations.
The VC growth playbook is broken for database startups. New entrants need clear differentiation and sustainable business models, not just funding. As a result, developers betting on niche databases should evaluate acquisition risk—will this company exist in three years? The winners get acquired (Neon, CrunchyData) or they fail (Fauna, Voltron Data).
MongoDB vs FerretDB: Legal Threat to Open-Source
MongoDB sued FerretDB in Delaware District Court on May 23, 2025, for patent infringement and API compatibility. The lawsuit targets FerretDB’s Apache 2.0-licensed software that translates MongoDB wire protocol queries into SQL for PostgreSQL backends, enabling MongoDB API compatibility without MongoDB’s proprietary database.
Unlike Oracle versus Google—where the Supreme Court ruled for Google on copyright fair use grounds—this is a patent case targeting functional compatibility itself. MongoDB claims FerretDB infringes patents covering aggregation pipeline processing and write operation reliability. No legal precedent exists for patent-based API compatibility claims.
“MongoDB’s lawsuit raises unprecedented questions about database system intellectual property,” Pavlo warns. If MongoDB wins, every open-source project building compatibility layers—MySQL-to-PostgreSQL migration tools, AWS-compatible APIs, vendor escape hatches—faces legal uncertainty. Therefore, developers building compatibility tools need legal review; users should monitor the case’s outcome closely.
Format Wars: Five Challengers vs 15-Year-Old Parquet
Five new columnar formats launched in 2025—Vortex, F3, FastLanes, AnyBlox, and Amudai—promising 10-100x performance gains over Parquet, which was designed for Hadoop-era HDFS storage 15 years ago. Vortex, now a Linux Foundation project, claims 100x faster random access, 10-20x faster scans, and 5x higher write throughput compared to Parquet.
The performance gains are real: SIMD-optimized compression, GPU compatibility, and designs optimized for S3-first architectures rather than Hadoop. In fact, F3 from Carnegie Mellon matches or exceeds Parquet’s decompression speed with comparable compression ratios. FastLanes exploits inter-column correlations that Parquet can’t leverage.
“Workloads have changed—we now mix wide scans with point lookups, handle embeddings and images, and run on S3-first stacks,” Pavlo explains. “We can get much better performance by applying new approaches.”
However, format fragmentation creates interoperability challenges. Data engineers running analytical workloads on S3 should benchmark new formats, but migration costs and tooling compatibility matter. Parquet still works fine for established pipelines. Evaluate carefully: performance gains versus ecosystem stability.
What This Means for 2026
The database industry matured in 2025. PostgreSQL-first is becoming the default strategy unless specific requirements demand specialized databases. AI integration via MCP servers is mandatory, not optional—but security implementations must catch up to adoption. Moreover, market consolidation will continue with more acquisitions likely, while the MongoDB versus FerretDB case will set precedents for open-source compatibility layers.
Engineering leaders should reconsider specialized database bets and default to PostgreSQL plus extensions. Implement MCP servers with proper authentication and access controls. Monitor MongoDB’s lawsuit outcome if building compatibility layers. Benchmark new columnar formats for S3-first analytics but weigh migration costs against performance gains.
The shift from specialized to general-purpose databases isn’t speculation—it’s $1.25 billion in validation.