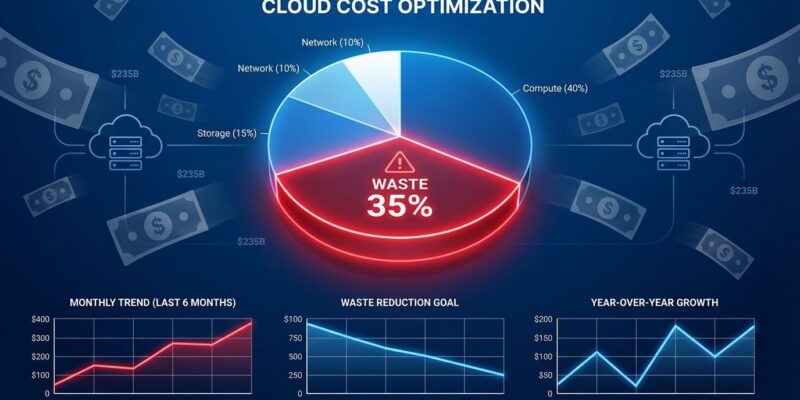
The global cloud computing market hit $840 billion in 2026, but industry data reveals a troubling reality: companies waste 28-35% of that spending—$235 to $294 billion annually—on idle resources, misconfigured instances, and unused capacity. Despite years of FinOps initiatives and cost optimization tools, the waste percentage hasn’t budged. The problem isn’t technical ignorance. It’s systemic dysfunction: 54% of waste stems from lack of visibility, 50% blame pricing complexity, and misaligned incentives between engineering and finance teams guarantee the hemorrhaging continues.
The Organizational Failure Behind Cloud Waste
Cloud waste persists because organizational systems actively incentivize it. Engineers don’t see the bill when they deploy resources—54% of companies lack cost visibility at the team level. Finance teams don’t understand technical trade-offs well enough to challenge engineering decisions. Consequently, this creates a classic principal-agent problem: developers optimize for shipping speed (their performance metric), not cost efficiency (finance’s metric). Nobody owns cloud costs, so waste flourishes in the accountability vacuum.
Pricing complexity makes this worse. AWS averages 197 distinct monthly price changes, with spot instance prices fluctuating continuously. Developers can’t accurately estimate costs even with years of experience, so they over-provision “to be safe.” That defensive over-provisioning accounts for a massive chunk of the waste—better to burn budget than risk a performance incident. Moreover, when 50% of organizations cite pricing opacity as a barrier to cost control, it’s worth asking: is this complexity accidental or strategic? Simpler pricing would enable accurate cost prediction, reduce over-provisioning, and make cross-provider comparison easier. Vendors benefit from opacity.
Kubernetes Cost Trap: 91% Can’t Optimize
Kubernetes epitomizes the cloud waste problem. 98% of enterprises report K8s as a major cost driver, yet 91% can’t effectively optimize their clusters. The same complexity that makes Kubernetes powerful—bin-packing, autoscaling, multi-tenancy—makes cost attribution nearly impossible. Which team owns that pod? Why is this namespace consuming 40% of cluster resources? How much do cross-zone service calls actually cost? Most organizations have no idea.
Over-provisioned resource requests and limits are endemic. Teams set CPU requests at 2 cores “just in case” when actual usage averages 0.3 cores. Furthermore, cluster autoscalers provision nodes for capacity that never materializes. Missing resource quotas mean a single runaway job can balloon costs overnight. The harsh reality: unless you have 50+ microservices or genuine multi-cloud portability requirements, Kubernetes complexity likely exceeds its value. That 91% optimization failure rate suggests most organizations adopted K8s for resume-driven development, not business necessity.
Proven FinOps Programs Cut 25-30% Costs
The good news: companies with structured FinOps programs consistently achieve 25-30% cost reductions, proving waste is preventable. A global insurer saved $17 million annually—$6 million in quick wins (idle VMs, unattached volumes), plus another $11 million from rightsizing and reserved instance optimization. An adtech company cut AWS spending 62% by eliminating forgotten test environments and rightsizing production workloads. Success requires three elements: executive sponsorship for cross-functional authority, engineering buy-in so cost becomes an engineering metric, and automation to detect and remediate waste at scale.
The progression is consistent. Start with showback—educational cost reports to teams without financial consequences. Visibility alone reduces waste 15-18% as engineers realize their services cost $40K monthly, not $5K. However, graduate to chargeback once FinOps culture matures: teams own their budgets and hit P&L statements, driving an additional 22% reduction through direct accountability. Capture quick wins first (idle resources, obvious over-provisioning), then iterate toward continuous optimization through automation and cultural embedding.
Cloud Repatriation: 86% of CIOs Rethink Strategy
Here’s the uncomfortable truth cloud vendors don’t want discussed: 86% of CIOs plan to move some workloads back from public cloud to private infrastructure—the highest repatriation rate ever recorded. This isn’t wholesale cloud rejection; it’s strategic reevaluation. For stable workloads with heavy data transfer (AI/ML training with GPUs, data-intensive applications), on-premises infrastructure delivers 30-60% cost savings over a 12-36 month horizon. 37signals famously saved $1 million annually moving email and services back on-premises. GEICO saw cloud costs increase 2.5x after migrating 600 applications to AWS.
The “cloud is always cheaper” narrative is dead. Public cloud makes economic sense for variable workloads, global distribution, and rapid scaling. Nevertheless, for predictable 24/7 workloads with minimal elasticity requirements, the TCO calculation often favors private infrastructure. Gartner predicts 40% of enterprises will adopt hybrid compute in mission-critical workflows by 2027, up from just 8% previously. The future isn’t cloud-first or on-premises-first—it’s workload-appropriate infrastructure placement.
Is Pricing Complexity Intentional?
Let’s ask the contrarian question: do cloud vendors benefit from pricing complexity? AWS’s 197 monthly price changes and labyrinthine SKU structure aren’t accidents of scale—they’re features that make cross-provider comparison nearly impossible and lock in customers through sheer friction. Multi-cloud adoption (89% of enterprises use two or more providers) multiplies this complexity, forcing organizations to manage three different pricing models simultaneously. As a result, companies over-provision because they can’t predict costs, and they stay with incumbent vendors because switching costs are astronomical.
Vendors could simplify pricing tomorrow if they wanted. They don’t, because opacity serves lock-in. The solution isn’t better cost calculators—it’s demanding genuine pricing transparency and evaluating whether cloud economics actually work for your workload mix. Sometimes the right answer is “this belongs on-premises.”
Key Takeaways
- Cloud waste ($235-294B annually) is organizational failure, not technical incompetence. Broken incentives and lack of visibility guarantee waste continues.
- Start with visibility before optimization. Implement tagging and showback first—visibility alone cuts waste 15-18%. Don’t buy expensive FinOps platforms until you’ve captured quick wins.
- Question Kubernetes adoption. If 91% of organizations can’t optimize K8s effectively, maybe most shouldn’t have adopted it in the first place. Complexity creates its own costs.
- Challenge “cloud is always cheaper.” Evaluate workload characteristics honestly. Stable, predictable workloads often cost 30-60% less on-premises over multi-year horizons.
- Demand pricing transparency from vendors. Complexity serves vendor lock-in. Push back on opaque SKU structures and frequent price changes that make cost prediction impossible.