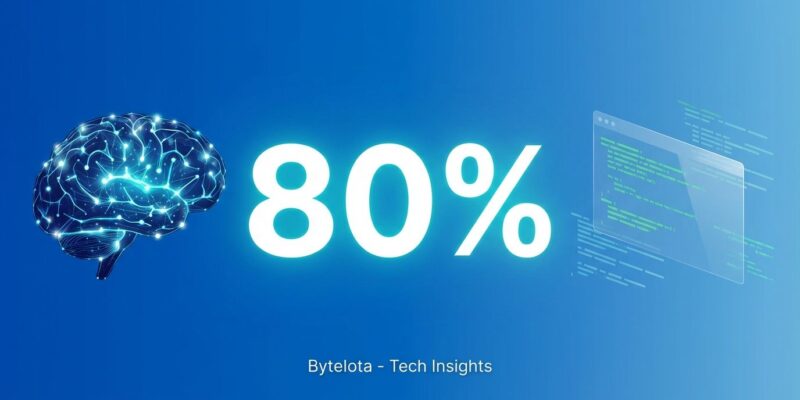
Anthropic launched Claude Opus 4.5 on November 24, 2025, becoming the first AI model to score over 80% on SWE-Bench Verified—a rigorous benchmark testing real-world software engineering tasks from actual GitHub issues. The model scored 80.9%, edging out OpenAI’s GPT-5.1-Codex-Max (77.9%) and Google’s Gemini 3 Pro (76.2%). Moreover, the release comes just six days after Anthropic’s valuation soared to $350 billion following $15 billion in investments from NVIDIA and Microsoft.
The 80% Milestone: Real GitHub Issues, Not Toy Problems
SWE-Bench Verified isn’t a typical AI benchmark. Instead, it tests models on 2,294 real GitHub issues from popular Python repositories, requiring the AI to understand, modify, and test actual codebases—not solve competition-style puzzles. Consequently, Opus 4.5’s 80.9% score makes it the first model to cross the symbolic 80% threshold, suggesting it can handle production-quality code generation at unprecedented levels.
The model also leads on 7 out of 8 programming languages on SWE-Bench Multilingual and scored 89.4% on Aider Polyglot coding problems. However, here’s the real validation: Opus 4.5 outscored every human candidate on Anthropic’s internal performance engineering exam, completed within a 2-hour time limit using parallel test-time compute.
The $350 Billion Context: Timing Isn’t Coincidental
On November 18, 2025—just six days before the Opus 4.5 launch—Anthropic’s valuation jumped from $183 billion to $350 billion after securing $15 billion in investments: $10 billion from NVIDIA and $5 billion from Microsoft. Furthermore, Anthropic committed to purchasing $30 billion in Azure compute capacity, signaling Microsoft’s strategy to reduce dependence on OpenAI by backing a direct competitor.
The timing matters. Specifically, Opus 4.5’s 80% SWE-Bench score provides immediate, measurable validation for that $350 billion valuation. Indeed, investors bet big on November 18; Anthropic delivered a technical breakthrough on November 24.
Developer Implications: Competing with Copilot and Cursor
Anthropic positions Opus 4.5 as “the best model in the world for coding, agents, and computer use,” directly challenging GitHub Copilot ($10/month), Cursor, and other AI coding assistants. Additionally, the company slashed prices by 66%—from $15/$75 per million tokens to $5/$25—making enterprise adoption more viable, though still pricier than GPT-5’s $1.25/$10.
Alongside the model, Anthropic released Claude for Chrome and Claude for Excel to general availability, expanding beyond pure coding into workflow automation. Meanwhile, the model also delivers 76% fewer tokens than Sonnet 4.5 at medium effort while maintaining the same performance, addressing practical deployment concerns about cost.
The Reality Check: Mixed Developer Reactions
Developer community reactions split sharply. As one Hacker News comment noted: “On r/singularity, treated as gospel; on Hacker News, dismissed as marketing fluff; in engineering Slack channels, met with a nervous laugh.” Some early testers report tasks that were “near-impossible” for Sonnet 4.5 just weeks ago now work with Opus 4.5. Conversely, others saw minimal productivity gain, with one developer noting, “After switching back to Sonnet 4.5, I kept working at the same pace.”
Simon Willison, an AI expert, captured the broader challenge: “Evaluating new LLMs is increasingly difficult” as benchmarks saturate and real-world differentiation becomes harder to measure. The key question remains: Does an 80% SWE-Bench score translate to production coding effectiveness, or is this benchmark-chasing with marginal real-world impact?
Key Takeaways
- First 80%+ SWE-Bench score: Opus 4.5’s 80.9% marks a milestone, beating GPT-5.1 (77.9%) and Gemini 3 Pro (76.2%) on real GitHub issues
- Validates $350B valuation: Launched 6 days after massive NVIDIA/Microsoft investments, providing measurable technical proof
- Competes with Copilot/Cursor: 66% price reduction and Chrome/Excel integrations target developer workflows directly
- Mixed real-world reception: Community skepticism remains—test on your own workflows, don’t trust benchmarks alone