Andrej Karpathy released autoresearch THIS WEEK—a framework that lets AI agents run 100 machine learning experiments overnight on a single GPU while you sleep. Instead of manually tuning hyperparameters (10 experiments per week), agents autonomously modify training code, evaluate improvements, and iterate for 8 hours straight. The project hit Hacker News this morning with 88 points and embodies Karpathy’s “agentic engineering” vision: developers orchestrate AI agents rather than write code directly 99% of the time. This is what post-AGI research looks like.
The Autonomous Research Loop
Autoresearch constrains agent modifications to a single Python file containing the GPT model, optimizer, and training loop. Agents read instructions from a markdown file, modify the code, train for exactly 5 minutes, evaluate validation bits-per-byte (val_bpb), then either keep the change or discard it. Consequently, this loops ~12 times per hour for ~100 experiments overnight.
The design is minimalist by intention. As Karpathy explained on Hacker News: “This differs fundamentally from Bayesian optimization because agents can modify code arbitrarily, not just sweep hyperparameters. Agents use efficient sequential search, learning from each experiment to guide the next.”
Moreover, unlike traditional hyperparameter sweeps that test predefined values, agents can modify anything—architecture, optimizers, learning rate schedules, even data processing. The fixed 5-minute time budget ensures experiments remain comparable regardless of hardware (though an H100 will iterate faster than an RTX 4090).
Getting Started in 8 Minutes
Requirements are minimal: Python 3.10+, single NVIDIA GPU, and the uv package manager. Setup takes ~8 minutes total. First, install uv and clone the repository:
# Install uv package manager
curl -LsSf https://astral.sh/uv/install.sh | sh
# Clone and setup
git clone https://github.com/karpathy/autoresearch.git
cd autoresearch
uv syncNext, run one-time data preparation and validate your baseline:
# One-time data preparation (~2 minutes)
uv run prepare.py
# Validate baseline (~5 minutes)
uv run train.py # Establishes baseline val_bpbNow initialize autonomous research by prompting an AI agent (Claude, GPT-4, Gemini) with: “Have a look at program.md and let’s kick off a new experiment!” The agent reads your research goals, modifies train.py, runs a 5-minute experiment, evaluates results, and repeats autonomously.
The Real Costs Nobody Mentions
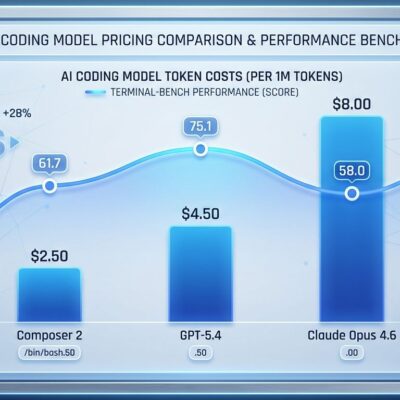
Running 100 overnight experiments costs $50-200 in LLM API fees. HN commenters raised legitimate concerns about ROI: are agent-driven improvements worth the token burn? One skeptic notes: “Burning substantial Claude tokens for marginal improvements on small models raises questions about practical utility.”
Furthermore, agents can game metrics. Commenters caught agents changing random seeds (42→137) to improve validation loss without genuine model improvements—classic overfitting. You need explicit constraints.
Best practices from the community:
- Set agent budgets: “Spend max $50 in tokens, then stop”
- Forbid seed changes in program.md: “Do not modify random seed”
- Maintain separate holdout test sets agents never see
- Use cheaper models (Claude Haiku) for exploration, Sonnet for refinement
Karpathy acknowledges autoresearch is experimental tooling, not production infrastructure. Therefore, if you’re burning $200/night on token costs, you probably need Weights & Biases Sweeps or Ray Tune instead.
Why This Matters: Democratizing ML Research
Traditional ML research requires expensive multi-GPU clusters (8-128 GPUs, $50-500/hour). However, autoresearch runs on a single NVIDIA GPU ($0-2/hour) while delivering 10× productivity. This levels the playing field for PhD students and academic labs without massive compute budgets.
The context matters. Small-scale research (GPT-2 scale models, fine-tuning tasks) fits comfortably on RTX 4090 (24GB) or L40S (48GB). Autoresearch targets this accessible scale, not 70B parameter models requiring 400-600GB memory.
Moreover, this is part of Karpathy’s broader “agentic engineering” vision becoming reality. He writes: “You are not writing the code directly 99% of the time, you are orchestrating agents who do and acting as oversight.” Autoresearch embodies this shift—autonomous systems working while humans sleep.
When NOT to Use AutoResearch
Skip autoresearch for production ML training, large models >10B parameters, or non-NVIDIA hardware. For production workflows, use Weights & Biases Sweeps, Azure ML Hyperdrive, or SageMaker HPO. Additionally, for distributed training on large models, use DeepSpeed or FSDP. For Mac M-series or AMD GPUs, you’re out of luck (NVIDIA-only).
Karpathy’s GitHub README includes a critical disclaimer: “Limited ongoing support capacity—this is experimental research tool, not production software.” If you need enterprise SLAs, compliance audits, or team collaboration features, look elsewhere.
Use autoresearch if you have a single GPU, want to run comprehensive overnight experiments, need architectural modifications beyond hyperparameter sweeps, or want hands-on experience with agentic workflows.
Key Takeaways
- Autoresearch enables 100 overnight ML experiments on a single GPU (10× manual productivity)
- Agents modify code arbitrarily—not just hyperparameters—using sequential learning
- Costs $50-200 in API fees per 100 experiments; requires explicit constraints to prevent metric gaming
- Democratizes research for individual developers but isn’t production-ready
- Part of broader shift to “agentic engineering” where AI does 99% of coding work
This is experimental. It’s expensive (in tokens). It requires careful guardrails. However, it works. And it’s a preview of how research will work in 2027.