
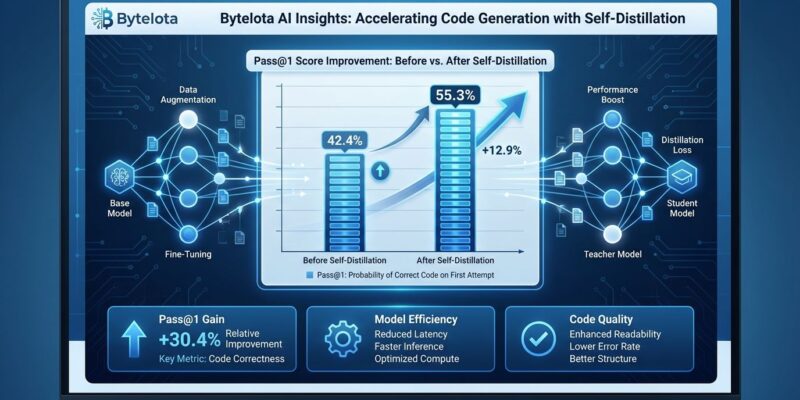
Apple researchers dropped a paper on April 1, 2026 that makes the AI training establishment look expensive and overcomplicated. Their “embarrassingly simple” self-distillation method improves code generation by 31%—boosting Qwen3-30B-Instruct from 42.4% to 55.3% pass@1 on LiveCodeBench v6—without reinforcement learning, teacher models, or verification systems. The technique: sample your model’s outputs with higher temperature, filter for basic correctness, then fine-tune on those samples. That’s it.
This matters because conventional wisdom says improving AI code generation requires expensive reinforcement learning infrastructure, access to larger teacher models, or sophisticated verification systems. However, Apple’s method costs roughly $5 to fine-tune a 7B model in 2026—the same as standard supervised learning—while RL approaches run orders of magnitude higher. Moreover, the paper, trending on Hacker News this week with 585 points and 172 comments, asks an uncomfortable question: has the field been stuck in an expensive equilibrium unnecessarily?
Three Steps to 31% Improvement
Simple Self-Distillation requires no exotic machinery. First, sample solutions from your frozen model using higher training temperature (0.8) and nucleus sampling (top-p 0.95) to generate diverse outputs. Second, filter those samples by basic syntax checks and execution correctness—no complex verification needed. Third, fine-tune the original model on the filtered dataset using standard supervised learning with cross-entropy loss. Consequently, the method works across Qwen3 and Llama 3.1 models from 4B to 30B parameters, including both instruct and thinking variants.
Furthermore, the code is publicly available on GitHub at apple/ml-ssd, and it integrates with the same fine-tuning infrastructure developers already use—LoRA, QLoRA, Unsloth. No proprietary tooling. No cloud-scale compute requirements. Individual developers can run this on accessible hardware, which is precisely what makes the “embarrassingly simple” framing sting. If improving models is this straightforward, why has the industry been burning money on complex alternatives?
Performance Gains on Hard Problems
The flagship Qwen3-30B-Instruct result jumps 12.9 percentage points on pass@1 and 18.1 points on pass@5 (53.5% to 71.6%). Nevertheless, the critical insight hides in the difficulty breakdown: hard problems improve by 15.3 percentage points while easy problems see smaller gains. The method makes models smarter on problems that actually challenge them, not just better at gaming simple test cases.
LiveCodeBench v6 provides the benchmark context—a contamination-controlled dataset with over 1,055 competitive programming problems from LeetCode, AtCoder, and CodeForces released between May 2023 and April 2025. Problems are annotated with release dates to evaluate on tasks published after the model’s training cutoff, preventing memorization. Additionally, current leaders include Gemini 3 Pro Preview at 91.7% and DeepSeek V3.2 Speciale at 89.6%. Qwen3-30B’s improved 55.3% still trails frontier models, but the 31% relative gain from such a simple technique narrows gaps that previously required massive compute advantages.
The Precision-Exploration Conflict Theory
The paper’s core theoretical contribution explains why this works: code generation creates a “precision-exploration conflict” that single temperature settings cannot resolve. Specifically, the researchers identify two position types. Locks have peaked distributions where syntax or semantics demand precision—”if n ==” needs the correct operator, not creative alternatives. Forks have genuinely plausible alternatives where algorithms or logic can vary—multiple valid ways to implement a sorting function or structure a loop.
Lowering temperature sharpens peaks at locks, suppressing distractors, but starves forks of the diversity they need for effective exploration. Conversely, raising temperature provides fork diversity but introduces noise at locks. SSD resolves this by reshaping token distributions asymmetrically based on context: it compresses distractor tails where precision matters while preserving and even increasing useful diversity where exploration matters. Importantly, the model learns when to be precise versus when to explore without any explicit labeling of lock versus fork positions—the distinction emerges from training on temperature-shifted samples.
Hacker News developers called this “the most compelling insight,” noting it matches intuition about how code works: some parts are constrained by syntax and semantics, others require creativity and problem-solving. The method teaches models this distinction through distribution reshaping rather than hard-coded rules.
Training on Garbage Still Helps
The researchers tested an extreme configuration: training temperature 2.0 with no truncation, producing samples so noisy that 62% contained no extractable code—pure gibberish. Surprisingly, the model improved anyway, gaining 5.7 percentage points (42.4% to 48.1% pass@1). This result challenges fundamental assumptions about learning from examples. We expect models need clean, correct training data to improve. Instead, SSD demonstrates that distribution reshaping provides gains even when most samples are broken.
The mechanism isn’t about memorizing correct solutions. Rather, it’s about learning which token distributions work better at locks versus forks, which emerges from comparing high-temperature samples (diverse but noisy) against the base model’s distributions. Even garbage samples teach the model something about probability mass allocation across different context types.
Why Self-Distillation Wasn’t Discovered Earlier
The “embarrassingly simple” framing borrows from “embarrassingly parallel” in computer science—a technical term meaning maximally simple. But it also carries subtext. The method uses standard supervised fine-tuning on model-generated outputs, techniques available for years. Publication came April 1, 2026. Hacker News discussion four days later centers on an obvious question: why didn’t anyone find this earlier?
The community debate points to orthodoxy traps. From 2023’s focus on supervised fine-tuning, the field shifted to 2026’s complex reinforcement learning techniques like GRPO (Group Relative Policy Optimization), which trains models through expensive trial-and-error with reward functions. Therefore, SSD counters that trend by showing simpler methods still have untapped potential. One comment captured the sentiment: “Field stuck in expensive equilibrium.” The assumption became that external signals—RL, teacher models, verifiers—were necessary for improvement. Simple self-improvement techniques got overlooked in the race toward complexity.
This matters beyond one paper. It’s a pattern recognition moment about AI research culture. How many other “embarrassingly simple” techniques are we missing because they feel too obvious? What other expensive paradigms rest on untested assumptions?
Key Takeaways
- Apple researchers’ Simple Self-Distillation improves code generation 31% (Qwen3-30B: 42.4% → 55.3% pass@1) using only temperature sampling, filtering, and standard fine-tuning
- No reinforcement learning, teacher models, or verification systems required—costs roughly $5 to fine-tune a 7B model, same as standard supervised learning infrastructure
- Gains concentrate on harder problems (+15.3 pp on hard split), indicating genuine capability improvement rather than gaming easy benchmarks
- Core innovation: resolves precision-exploration conflict by reshaping token distributions asymmetrically—compresses distractor tails at constraint-heavy positions while preserving diversity where exploration matters
- Training on 62% garbage samples still improves models by 5.7 pp, demonstrating mechanism works through distribution learning rather than memorizing correct solutions
- Code publicly available (github.com/apple/ml-ssd) and works with standard fine-tuning tools, democratizing model improvement for individual developers and small teams
- “Embarrassingly simple” framing raises meta-question: has AI field been stuck in expensive patterns unnecessarily, overlooking simpler techniques in race toward complexity?

