
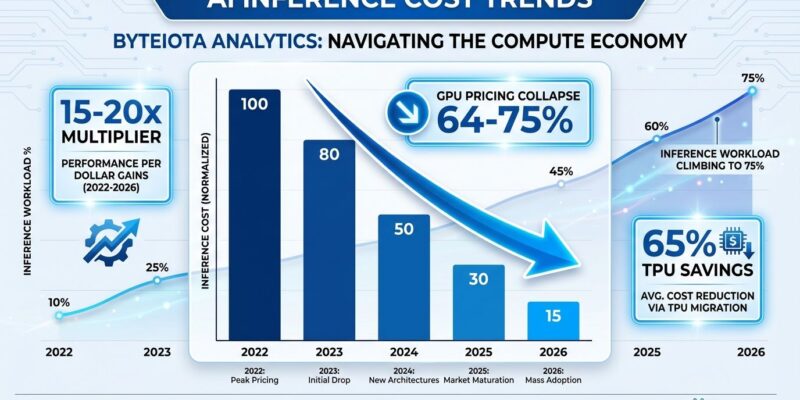
AI inference costs dominate the economics of deploying AI models in production, consuming 80-90% of total compute dollars over a model’s lifecycle. For every $1 billion spent training an AI model, organizations face $15-20 billion in inference costs over the model’s production lifetime. This 15-20x multiplier isn’t hypothetical—GPT-4’s training cost approximately $150 million, yet cumulative inference costs reached $2.3 billion by end of 2024. That’s the hidden truth most teams miss until six months post-launch when bills explode.
This economic reality is driving 2026’s defining market shift. Midjourney, Anthropic, and Meta are migrating from Nvidia’s GPU monopoly to Google TPUs, cutting costs 65% and fundamentally reshaping AI infrastructure economics. Industry analysts have declared 2026 “the year the GPU monopoly cracked.” If you’re building on AI today, these economics dictate your infrastructure strategy.
The Inference Cost Iceberg Nobody Talks About
Training gets the headlines. The $100 million model. The breakthrough architecture. Yet inference—the continuous, recurring cost of serving that model in production—crushes budgets at 15-20x the training expense. GPT-4 proves this precisely: $150 million training became $2.3 billion in inference costs within two years. Exactly 15x.
The workload distribution confirms this trend. Inference now represents 55% of AI infrastructure spending in early 2026, up from 33% in 2023. Moreover, projections show inference reaching 75-80% of all AI compute by 2030 as models move from research to production. Consequently, teams budgeting primarily for training costs are setting up budget crises 6-12 months after launch.
Here’s the planning rule most CTOs miss: allocate 80% of your AI budget to inference, not training. If you budget $100 million for training, plan $1.5-2 billion for inference over the model’s 2-3 year production life. Anything less is fantasy math that leads to painful vendor renegotiations or service cutbacks.
Midjourney’s 65% Cost Cut: Real-World TPU Migration Proof
In Q2 2025, Midjourney migrated its Stable Diffusion XL and Flux inference fleet from Nvidia A100/H100 GPUs to Google Cloud TPU v6e pods. The result: monthly inference costs dropped from $2.1 million to under $700,000—a 65% reduction representing $16.8 million in annualized savings. The migration took six weeks with zero downtime and achieved an 11-day payback period.
Let that sink in. The entire migration cost was recovered in less than two weeks of savings. This isn’t vendor marketing or theoretical benchmarks. This is a massive-scale production system serving millions of users, cutting costs by nearly two-thirds with documented results. Google’s TPU v6e delivers 4.7x better price-performance for inference workloads and consumes 67% less power than equivalent GPU clusters.
For any company spending $100,000+ monthly on inference, Midjourney’s case study de-risks TPU migration. The 11-day payback makes this an obvious ROI win, not a speculative optimization. Furthermore, the zero-downtime migration proves this isn’t bleeding-edge experimentation—it’s proven infrastructure engineering.
Anthropic’s Billion-Dollar TPU Bet Signals Market Inflection
In October 2025, Anthropic signed a contract with Google Cloud for up to one million TPUs worth tens of billions of dollars, bringing over one gigawatt of AI compute capacity online in 2026. When a company with a $7 billion revenue run rate makes a multibillion-dollar infrastructure commitment, that’s not a pilot project—that’s strategic repositioning.
Meta followed with its own multibillion-dollar TPU negotiations in 2025. These aren’t isolated incidents. They’re validation of a permanent market shift. The consensus is clear: 2026 is “the year the GPU monopoly cracked.” Analysts project Nvidia’s inference market share falling from 90%+ to 20-30% by 2028 as TPUs and specialized ASICs capture 70-75% of production inference workloads.
For smaller companies and startups, this validates multi-vendor strategies and de-risks TPU adoption. When Meta and Anthropic—historically massive Nvidia customers—commit billions to alternative accelerators, single-vendor Nvidia lock-in becomes a documented strategic risk, not a theoretical concern.
H100 GPU Pricing: The 64-75% Cloud Cost Collapse
Nvidia H100 cloud pricing fell 64-75% from Q4 2024 ($8-10/hour) to Q1 2026 ($2.99/hour). Jarvislabs, Lambda Labs, and RunPod all now offer H100 instances at $2.99/hour—a dramatic shift driven by supply improvements and competitive pressure from TPUs. However, direct H100 purchases tell a different story: $25,000-$30,971 per GPU, plus $50,000-$150,000 in infrastructure overhead for InfiniBand networking, power systems, cooling, and racks.
The buy vs rent economics are stark. Break-even point: 14 months of 24/7 utilization. For most use cases—training experiments, variable workloads, and research—cloud rental at $2.99/hour beats purchasing given that infrastructure overhead runs 3-6x the GPU hardware cost. Real-world example: training Llama 70B on 8 GPUs for five weeks costs $20,093 in the cloud vs $250,000 for owned hardware. Cloud wins by 12x for one-time training.
The 64-75% price collapse exposes GPU pricing volatility. Teams that locked into 2024 contracts at $8-10/hour are overpaying 3x vs current rates. Only constant 24/7 inference workloads lasting 18+ months justify GPU purchases—and even then, TPU migration offers superior economics with 65% proven savings.
Why the 280-Fold Efficiency Gain Still Isn’t Enough
Inference costs for GPT-3.5-level performance dropped 280-fold from November 2022 ($20 per million tokens) to October 2024 ($0.07 per million tokens). Hardware improvements deliver 30% annual cost reductions and 40% annual energy efficiency gains. Software optimizations achieved 33x energy reduction per prompt in just 12 months. These are stunning improvements that make AI economically accessible.
Yet total inference spending grew 320% despite per-token costs falling 280-fold. The paradox reveals the truth: usage scales exponentially faster than costs decline. Startups save 90% per request but see 10x traffic growth, resulting in doubled or tripled bills. The efficiency gains make AI viable, but they don’t eliminate inference as the dominant cost driver.
This reinforces why the 15-20x training-to-inference multiplier matters. Even with dramatic efficiency improvements, inference still dominates budgets at scale. Plan for it. Budget for it. Optimize for it. The math is unforgiving.
Strategic Implications: The Multi-Vendor Future
Companies building Nvidia-only infrastructure face “structural competitive disadvantage” as TPU and ASIC alternatives mature. The emerging best practice: train on Nvidia GPUs for ecosystem maturity and tooling depth, infer on TPUs for 65% cost savings, with abstraction layers enabling portability. Kubernetes, vLLM, and TensorRT provide the infrastructure independence that reduces vendor lock-in risk.
Hardware improves 30% annually in cost and 40% in efficiency. Consequently, committing to static 3-5 year hardware purchases means overpaying 30% in year two and 60% in year three. Design for annual refresh cycles, not long-term lock-in. The companies winning on AI economics in 2028 will be those that built flexibility into their 2026 infrastructure decisions.
Nvidia maintains 90%+ training dominance due to CUDA’s ecosystem lead, PyTorch integration, and tooling maturity. That won’t change. However, inference is fragmenting. Multi-vendor strategies aren’t experimental anymore—they’re required for competitive cost structures. Infrastructure abstraction isn’t a 10% overhead tax; it’s a 65% long-term savings strategy.
Key Takeaways
- Budget 80% of AI spending for inference, not training: the 15-20x multiplier means $1B training costs become $15-20B inference costs over model lifetimes.
- TPU migration is proven at scale: Midjourney’s 65% cost reduction with 11-day payback de-risks the strategy for any company spending $100K+/month on inference.
- 2026 marks market inflection: Anthropic’s billion-dollar TPU contract and Meta’s negotiations signal permanent shift away from GPU-only infrastructure.
- H100 pricing dropped 64-75% in 14 months: cloud rental at $2.99/hour beats purchasing for most workloads given 3-6x infrastructure overhead costs.
- Single-vendor lock-in creates structural disadvantage: design for multi-vendor strategies with abstraction layers (Kubernetes, vLLM, TensorRT) enabling portability.
- Plan for 30% annual cost improvements: committing to 3-5 year static hardware means overpaying as hardware and software efficiency compounds annually.
The inference economics of 2026 demand strategic infrastructure planning. The teams that win will be those that recognize inference as the dominant cost driver, embrace multi-vendor strategies, and design for flexibility over vendor lock-in. The GPU monopoly cracked. Plan accordingly.



