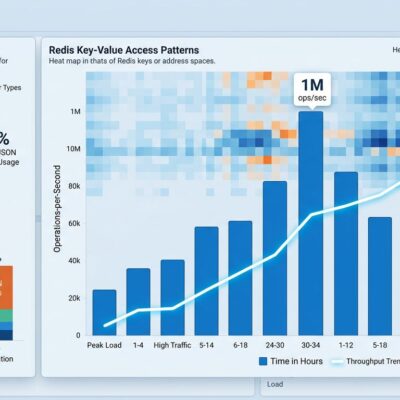
A January 2026 study analyzing 3,042 production Kubernetes clusters reveals a $50 billion problem hiding in plain sight: 68% of pods request 3-8x more memory than they actually use. Companies are burning an average of $847 per month on memory they’re paying for but never using—not because teams are incompetent, but because the industry built a system that makes waste inevitable.
The Hidden Tax on Every Kubernetes Deployment
After tracking 847,293 pods across 600+ companies, Wozz’s recent study uncovered the scale of Kubernetes memory overprovisioning. The numbers are staggering: individual clusters waste between $50,000 and $500,000 annually, with the largest single case hemorrhaging $2.1 million per year on unused memory.
The breakdown by application type reveals which workloads bleed the most:
| Type | Avg Requested | Avg Used (P95) | Waste Ratio |
|---|---|---|---|
| Node.js | 1.8 GiB | 587 MiB | 3.1x |
| Python/FastAPI | 2.1 GiB | 612 MiB | 3.4x |
| Java/Spring Boot | 3.2 GiB | 1.1 GiB | 2.9x |
| AI/ML Inference | 16.4 GiB | 2.7 GiB | 6.1x |
AI and ML workloads are the worst offenders, with 84% overprovisioned and teams requesting 16.4 GiB while actually using just 2.7 GiB—a 6.1x waste multiplier. This isn’t a rounding error. With global cloud spending projected to exceed $840 billion in 2026 and 28-35% of that being pure waste, Kubernetes overprovisioning represents tens of billions in unnecessary costs.
Here’s the kicker: cloud providers bill you for requested memory, not used memory. Request 2 GiB and use 400 MiB? You’re paying for 2 GiB. The incentive structure rewards waste.
Why Cargo-Culted Configs Are Bleeding You Dry
The Wozz study traced 73% of memory: "2Gi" configurations back to three sources: official Kubernetes documentation examples, Stack Overflow answers from 2019-2021, and Helm charts with “safe” defaults. Developers aren’t being lazy—they’re following industry best practices. The problem is those best practices are designed to prioritize safety over efficiency, and nobody questions them.
Here’s the typical sequence: A developer needs to deploy a new service. They check the Kubernetes docs or search Stack Overflow for “kubernetes memory request example.” They find memory: "2Gi" in every tutorial. They copy-paste it. It works. They move on. Five years later, that config is still running, burning $500/month on memory the pod never touches.
The study found that only 12% of teams could answer what their P95 memory usage was without looking it up. Most teams don’t monitor actual resource consumption—they set resources at deploy time and never revisit them. This “set and forget” culture is the industry standard, not the exception.
The Psychology of OOM Trauma
Here’s where it gets interesting. The study interviewed engineering teams and found that 64% admitted to adding 2-4x memory headroom after experiencing a single OOMKilled event. One traumatic incident—a pod crashing because it ran out of memory—creates permanent paranoia that manifests as 4x overprovisioning that never gets questioned again.
But the data doesn’t support this fear. Teams that rightsized their memory requests saw OOMKill rates increase from 0.02% to 0.03%—a statistically insignificant change. The study also found that 94% of memory spikes are better handled by horizontal scaling (adding more pods) rather than vertical padding (giving each pod more memory).
Yet fear trumps data. One OOMKilled event creates a trauma response: “We can’t let that happen again.” The solution? Quadruple the memory and never look back. It’s expensive insurance against a problem that barely exists.
The Embarrassingly Simple Fix Nobody Uses
The recommended formula is almost insultingly straightforward:
memory_request = P95_actual_usage × 1.2That 1.2x multiplier provides 20% headroom for traffic spikes without the 3-8x waste. Apply this formula and you’re instantly cutting memory costs by 60-75%.
Real-world examples bear this out. An AI startup reduced requests from 16 GiB to 3.4 GiB based on actual P95 usage and saved $433,000 per year. An e-commerce platform optimized 487 microservices and cut costs by 52%, saving $197,000 annually. A fintech startup saved $34,000 per year—the equivalent of two additional months of runway.
The fix isn’t complex. It’s embarrassingly simple. But adoption is near zero because it requires two things most teams don’t have: visibility into actual resource usage and the willingness to revisit “working” configurations.
Here’s what right-sizing looks like in practice:
# BEFORE: Cargo-culted from docs (3.4x waste)
resources:
requests:
memory: "2Gi" # Copied from K8s docs
limits:
memory: "2Gi"
# AFTER: Data-driven rightsizing (P95 = 587MiB)
resources:
requests:
memory: "704Mi" # 587MiB × 1.2 = 704Mi
limits:
memory: "704Mi"That single change, multiplied across your cluster, can recover hundreds of thousands in annual waste.
FinOps Automation: Admitting We Can’t Be Trusted
The industry’s response to this crisis is telling. By the end of 2026, 75% of enterprises will adopt FinOps automation platforms. These tools use AI and machine learning to continuously analyze clusters and automatically rightsize resources in real-time. Mature organizations deploying these platforms report 40% reductions in cloud overspend. Tools like Cast AI claim to consistently deliver cost savings exceeding 60%.
FinOps automation is essentially the industry admitting that humans can’t be trusted to size resources correctly. We’re too afraid of OOMKills, too reliant on outdated Stack Overflow answers, and too busy to revisit configurations that “work.” So we’re building AI to clean up our mess.
The trajectory is clear: autonomous cost management is replacing manual quarterly reviews. Non-production environments automatically power down when idle. Kubernetes clusters scale intelligently based on demand. Unused storage archives itself. The tools exist, and adoption is accelerating.
But automation is a band-aid on a cultural problem. The real issue is that Kubernetes resource management was designed in a way that makes waste the default behavior. Official docs encourage “safe” defaults without teaching measurement. Community knowledge is frozen in 2019. Helm charts ship with conservative configs that nobody questions. Cloud providers profit from overprovisioning because they bill on requests, not usage.
What This Means for Your Cluster
If you’re running Kubernetes in production, you’re almost certainly overprovisioned. The study found that average cluster utilization sits at just 13-25% for CPU and 18-35% for memory. That means 65-87% of your CPU and 62-82% of your memory is sitting idle while you pay full price.
Start by answering one question: What’s your P95 memory usage? If you can’t answer that without checking your monitoring tools, you’re in the 88% majority that’s flying blind. Install a tool like kubectl top, analyze your actual usage over 24 hours, and apply the P95 × 1.2 formula. You’ll likely find you can cut 60-70% of your memory requests without meaningful risk.
The Kubernetes memory overprovisioning crisis isn’t a technical problem—it’s a cultural and systemic one. But unlike many systemic problems, this one has an embarrassingly simple fix. The question is whether you’re willing to revisit configurations that “work” to recover the money you’ve been burning for years.