Three AI agent memory systems gained 1,377 combined GitHub stars today, and they’re telling us something important: we’ve been using the wrong tool for the job. For months, developers have shoehorned RAG pipelines into every AI agent that needed memory, setting up vector databases and embedding APIs just to remember what happened in the last session. It’s architectural overkill, and the industry is finally calling it out.
The evidence is landing in real-time. memvid (Rust), claude-mem (TypeScript), and memU (Python) all trended today with a collective 1,377 stars. These aren’t marginal improvements on RAG. They’re a different category: lightweight memory layers built for context persistence, not document retrieval. And they’re 10x cheaper and 50x faster than traditional RAG for what most agents actually need.
RAG Was Built for the Wrong Problem
RAG excels at knowledge retrieval. You have a massive corpus of documents and need to find semantically relevant passages? RAG is your solution. Vector databases, embeddings, similarity search, re-ranking—all justified when you’re searching across millions of tokens.
However, AI agents don’t need that. They need to remember what happened yesterday. What decisions were made. What the user’s coding style is. What bugs were fixed in the last session. That’s not a semantic search problem—it’s a context persistence problem.
The traditional RAG stack brings absurd overhead to this simpler task:
- Infrastructure: Spin up Pinecone or self-host Weaviate ($70-100/month)
- Embedding generation: Every query hits OpenAI’s embedding API (100-200ms, $0.02/1M tokens)
- Vector search: Similarity calculations across your index (50-300ms)
- Complexity: Chunking strategies, retrieval tuning, index maintenance
Total latency: 150-400ms. Total cost: $100-200+/month at modest scale. And for what? To remember that the user prefers tabs over spaces?
The Memory Layer Alternative
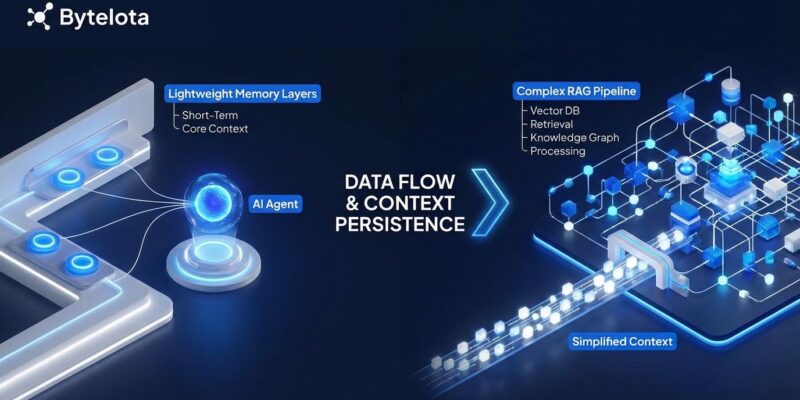
Today’s trending repositories represent a pattern, not three isolated projects. They’re converging on a simpler architecture: key-value storage with compression and time-aware retrieval. No embeddings. No vector databases. No semantic search.
memvid takes the most radical approach: a single portable .mv2 file containing your entire agent memory. Append-only, immutable frames inspired by video encoding. Sub-5ms local access. Offline-capable. Crash-safe with time-travel debugging. Consequently, it’s memory you can copy to a USB drive and run on a field device with zero network dependency.
claude-mem targets Claude Code users with a zero-configuration integration. Five lifecycle hooks capture session observations automatically—no manual logging. SQLite for full-text search, Chroma for optional vector operations, and a progressive disclosure system that achieves 10x token savings by returning compact indexes before full details. Install it and forget it exists. It just works.
memU goes hierarchical: raw data flows into discrete items (preferences, skills, habits), which aggregate into category summaries (preferences.md, work_life.md). Dual retrieval combines fast RAG-style vector search with slower LLM-based semantic reasoning, plus query rewriting that uses context awareness to resolve pronouns. It’s the most sophisticated of the three—LLM-native memory infrastructure that gets smarter over time.
The Economics Are Brutal
Let’s run the numbers on 10,000 agent sessions per month.
RAG pipeline costs:
- Vector DB hosting: $70-100/month (Pinecone starter or self-hosted Weaviate)
- Embedding API calls: ~$20/month (OpenAI text-embedding-3-small)
- Query latency: 150-400ms average (embedding generation + vector search)
- Total: $100-200+/month
Memory layer costs (memvid example):
- Storage: $0.10/month for 1GB session data (S3 standard)
- Retrieval: <5ms local SSD access, zero API calls
- Infrastructure: None—embedded in your application
- Total: <$10/month
As a result, that’s a 10x cost reduction and 50x latency improvement. For context persistence, memory layers aren’t just simpler—they’re economically superior.
When to Use What
This isn’t an either-or situation. Both architectures have legitimate use cases.
Use memory layers when you need:
- Session continuity across agent restarts
- Conversation history and workflow state
- User preferences and learned behaviors
- Offline or edge deployment (no network dependency)
Use RAG pipelines when you need:
- Semantic search across large document corpora
- Dynamic knowledge retrieval from external sources
- Relevance ranking across millions of passages
Use hybrid architectures when you need both: Enterprise agents often require context persistence (memory layer) plus knowledge retrieval (RAG). For example, a customer support bot remembering conversation history while searching a knowledge base. A coding assistant tracking project decisions while retrieving framework documentation. These justify the added complexity of running both systems.
Implementation Patterns
The pure memory layer pattern is dead simple: agent captures observations, compresses them into summaries, stores locally, loads context on next session. No external services. No API calls. claude-mem demonstrates this with Claude Code—install the plugin, and every session automatically has access to previous work.
Meanwhile, the pure RAG pattern remains necessary for document-heavy use cases: generate query embedding, search vector index, re-rank results, inject top-K passages into context. LangChain and LlamaIndex excel here because the complexity is inherent to the problem.
The hybrid pattern layers them: memory for session state, RAG for knowledge augmentation. Your agent maintains continuity through the memory layer while pulling in relevant external knowledge through RAG when needed. More moving parts, but both justified by distinct requirements.
Why This Is Happening in 2026
This isn’t random. Four converging trends are driving the shift.
First, agentic AI is moving from research demos to production systems. Every agent needs memory, and developers are discovering RAG doesn’t fit. Second, the Model Context Protocol hit 10,000 servers, creating demand for memory infrastructure that integrates cleanly. Third, long context windows (200K-1M tokens) remain expensive—compressing context into persistent memory is cheaper than stuffing everything into prompts. Finally, as AI moves to edge devices and offline environments, cloud-dependent vector databases become dealbreakers.
The market is responding. Agent frameworks will integrate memory layers as defaults within months. “Memory as a Service” startups will launch this year. By 2027, expect LLM providers to build native memory features, commoditizing what today requires third-party tools.
The Takeaway
If you’re building AI agents in 2026, you need a memory strategy. The days of defaulting to RAG for everything are ending. Ask yourself: do I need semantic search across a knowledge base, or do I need to remember what happened last session? The answer dictates your architecture.
For most agents, that answer is context persistence. And today’s trending repositories are showing you how to build it without the overhead.