Sixty-three percent of teams running OpenTelemetry Collectors say configuration management is their number one problem. Not features. Not vendor support. Getting the thing configured and keeping it that way. This is from the project’s own follow-up survey. The project heard it. Blueprints is the response.
OpenTelemetry launched the Blueprints and Reference Implementations initiative this week, publishing prescriptive deployment guidance directly at opentelemetry.io/docs/guidance/blueprints. This is not a new release. There is no new API. It is something more useful: the project telling you, officially, how to set this up.
What Blueprints Actually Are
A Blueprint is a living document scoped to a specific deployment environment. Each one maps out the common pain points for that environment, a recommended architecture, and concrete implementation steps. The project is not publishing a single universal deployment model — different environments need different patterns. You pick the blueprints that match your stack.
Three focus areas launched first: Kubernetes observability, infrastructure outside Kubernetes (VMs, bare metal, hybrid), and centralized telemetry platform architectures. Alongside these, three reference implementations went live — from Adobe, Mastodon, and Skyscanner — showing how real production deployments look, not how a vendor wants you to think they look.
The Mastodon implementation is worth noting. Because Mastodon is decentralized, each server operator decides independently whether to collect telemetry and where to send it. OTel’s environment variable-based configuration made that operator autonomy practical. That is a real use case you will not find in a vendor’s getting-started guide.
The Kubernetes Blueprint in Practice
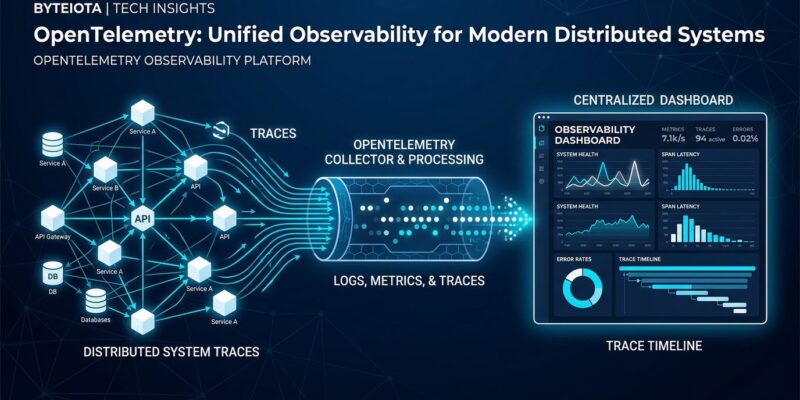
The Kubernetes blueprint formalizes a two-tier architecture that experienced OTel teams have converged on through trial and error. Tier one is a DaemonSet: one Collector per node, collecting host-level metrics and node-level logs, automatically enriching telemetry with Kubernetes metadata via the k8sattributes processor. Pod name, namespace, and node label attribution happen without manual instrumentation.
Tier two is a Gateway Deployment: a centralized Collector that handles the expensive work — Tail-Based Sampling, batching, and routing to multiple backends. This separation is deliberate. DaemonSet agents stay lightweight and close to the workload. The Gateway handles decisions that require cluster-wide context.
If your team has been running a single Collector and wondering why it struggles to keep up, this two-tier pattern is the answer the Blueprint makes explicit.
Why the Project Did This Now
OpenTelemetry graduated from the CNCF on May 11, earning the foundation’s highest maturity level. Its JavaScript API package now sees over 200 million monthly downloads. It is not a project on its way up — it is infrastructure. And infrastructure that 65% of teams run across more than 10 Collector instances gets held to a different standard than a promising experiment.
The OTel project’s historical philosophy was deliberately vendor-neutral: give teams building blocks, let them decide. That approach worked for adoption. It created friction for operations. The Collector survey data makes the failure mode concrete: teams were not struggling to understand what OTel could do. They were struggling to agree on how to deploy it without breaking things.
The announcement text is direct: end users want a prescriptive, opinionated way of deploying OpenTelemetry as recommended by the project. Not more options — a recommendation. Blueprints is the project finally making one.
This pattern plays out repeatedly in cloud-native tooling. Kubernetes gave teams maximum flexibility with YAML. Helm and Operators emerged because raw YAML flexibility was not what teams needed at scale. React was unopinionated. Next.js succeeded by being opinionated. The Blueprints initiative is OTel reaching the same conclusion: flexibility without defaults is a tax, not a feature.
What to Do Now
If you are running OpenTelemetry in production, read the blueprints relevant to your environment and compare them against your current setup. The gaps are likely where your pain points live.
If you are evaluating OTel or planning a new deployment, start with the blueprint rather than a blank Collector config. For Kubernetes, that means beginning with the two-tier DaemonSet and Gateway architecture and adjusting from there.
For production context, the three reference implementations from Adobe, Mastodon, and Skyscanner show how organizations at different scales approached the same problems. InfoQ’s coverage includes additional commentary on what the enterprise teams involved wanted from the initiative.
The project is treating Blueprints as living documents — they will be updated as the ecosystem evolves. The recommendation you follow today will not be silently wrong six months from now. That is a meaningful commitment for anyone who has dealt with OTel config drift.